The SUNCODAC interface.
The current version of the SUNCODAC user interface is that shown in Figure 1. In this section we will simply describe the main features of the Search screen. Search options and data retrieval will be discussed in more detail in the following section. Throughout this guide, roman bold type will be used for field labels in the search tool, while variable values will appear in bold italics.
Figure 1 The SUNCODAC interface
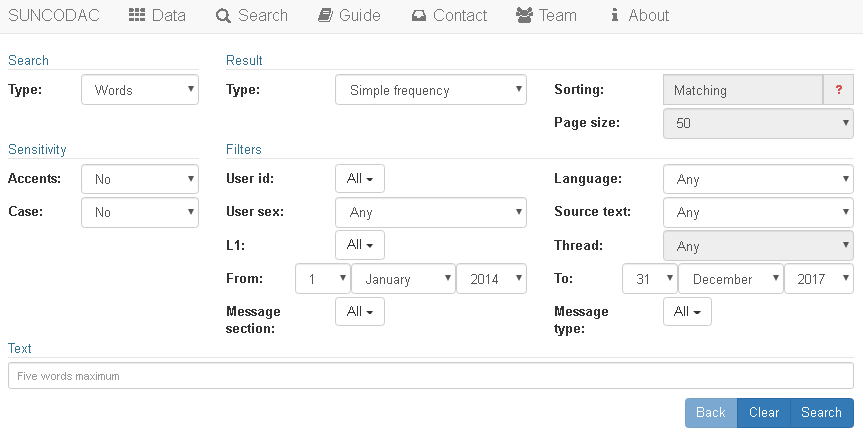
The SUNCODAC query tool allows for three types of search. The Search type Words returns all occurrences of the word or word sequence (up to a maximum of five words) typed in the search box (Text). The search can be done in the whole corpus or in a subset of texts delimited by selecting the relevant values for other fields in the search screen. With the option Words prox. we can look at words in the vicinity of other words (at a maximum distance of ten words between two search terms). For either of these two search types, the user can choose from three different output formats (Result type): 1) Simple frequency, showing the number of occurrences of the search term per total number of words in defined subcorpus; 2) Full frequencies, with the number of occurrences broken down by year, individual user, sex, L1 and L1 by sex; and 3) KWIC, a list of concordance lines which can be sorted (Sorting) by a combination of criteria including up to two preceding or following words.
To finetune the search, it is possible to activate (or deactivate) sensitivity to Case (capital and lowercase letters) and Accents distinctions. Both case and accent neutralization is a key feature in a corpus of informal written language, where users frequently deviate from standard spelling norms, and with an important non-native component.
A third search type, Browsing, retrieves whole texts. Combined with the relevant filters, it may be particularly useful, for example, to collect all the posts written by a given participant or a specific group, e.g. to describe individual or group style features. It is also possible to reconstruct entire threads (by combining values of the Source text and Thread fields), from the opening post containing the source text on which the discussion is based to the lecturer’s final comments. Metadata can be displayed by clicking on the up-pointing arrow to the left of each of the retrieved posts. Note, however, that summary and/or final comments, may be missing in some of the discussions, particularly during the first year the activity was implemented. The retrieved texts may then be downloaded for further analysis using different corpus analysis tools (on downloading, see below).
To facilitate results retrieval, Page size allows for the possibility of choosing the number of search results displayed on a single page, ranging from 50 to 1000. Note that the bigger the number of displayed items, the heavier to process, which may result in a significant display slowdown. The selection of page size is particularly relevant for downloading purposes, because only the search results actually shown on the search page can be downloaded. If results are displayed in different pages, each page is downloaded as a separate file.
As shown in Figure 1, metadata for each of the texts in the database have been recorded as a set of variables which may be used as filters for searching and browsing purposes. They are displayed as fields in the search screen with user-friendly dropdown menus containing the relevant values for each variable, as described below. The list of available variables is the following:
- Date (From...To): The date of the posts allows for the reconstruction of complete interactions where messages are arranged in their actual sequence, since the exact time at which each text was posted is included in the metadata. This field also makes it possible to define periods within a particular course term in order to explore changes over time in interaction patterns. The exact starting and ending dates for each discussion thread in the corpus holdings are listed in table form in this document.
- Author (User id): It is possible to restrict searches to the messages posted by a specific individual or group of individuals by ticking desired participant codes on the drop-down menu.
- User Sex and L1. Information on author’s sex and language background (Spanish/Galician, English, Chinese and Other) has also been incorporated in the metadata. Chinese speakers have been put in a separate category since this group is considerably larger than any other group of non-Spanish speaking students. The category Other is rather miscellaneous and consists mostly of European students of several nationalities including French, Italian, German or Polish, among others.
- Message type. Each forum discussion consists of different kinds of messages, including the source text, the initial translation proposal (draft) by the volunteer student (moderator) coordinating the discussion, feedback from his/her classmates, final summary by the moderator and final appraisal by one of the lecturers in charge of the course (final comments). Other exchanges between students, such as requests for clarification or brief follow-up comments, were classified as other.
- (Main) Language used in the post.
- Section of the post. Only applicable to the feedback message type. In order to refine searches through the corpus, recurrent sections were identified in the main body of the feedback messages: proposal, the core of the message, containing a detailed list of problems and suggestions for improvement; pre-proposal, including elements like an overall assessment of the translation, of the relative difficulty of the task, congratulations or a preview of criticism; post-proposal, which mirrors the pre-proposal section; opening and closing, of an epistolary nature, containing salutation and various farewell expressions.
- Source text and thread. Each interaction collected in SUNCODAC focused on the discussion of a specific excerpt and developed as a single discussion thread. Occasionally, two, or even three, discussions were held on as many different excerpts from the same source text. These are coded separately by means of the fields source text (text title) and thread (A, B or C, when relevant). A document containing a complete list of text titles (and threads) covered over the four years when data were collected for SUNCODAC can be found here. Starting and ending dates for each forum are also included to facilitate use of the date (From… To) fields in the SUNCODAC interface.
Source texts and first drafts were included in the database for corpus users to be able to understand cross-references in the messages. Task instructions were, however, left out since the same message was always used to start the debate, except for the excerpt to be discussed.
Using SUNCODAC. Tips
The Words search contains a single search box (Text) where we must specify the word or word sequence (up to a maximum of 5 words) that we intend to search in the corpus and clicking the Search button. This type of search is particularly useful to obtain information on the relative frequency of the word or expression in the corpus or in a particular section, depending on the filters that have been applied (a particular author, authors with a particular L1, a given time period, etc.) (see supra on filters). For a new search, click on clear and type the new search term or simply type the search term in the search box and press search.
The Words prox. search is useful to explore the tendency of two words to co-appear (collocations). We must type the desired words in the left and center search boxes, with the order indicating the search direction, while in the rightmost box, we may specify the desired distance between the two words. Two options are available: a fixed distance (the exact number of words separating the two searched words) and a range of words (the maximum number of separating words), up to 10 words in both cases. Words prox. is useful to identify instances of constructions whose constituents may be discontinuous, like perfect tenses, passive structures, etc. (see Figure 2 below). For example, typing I in the leftmost box, think in the center and choosing ≤3 in the rightmost one (①, ② and ③ in Figure 2 below) will allow us to track all instances of I think, but also of its negative form, I don’t think, I definitely think, I also think, etc.
For both the Words and the Words prox. searches, it is possible to make the search sensitive to either accent, case or both. The accent option is particularly useful to search the Spanish component of the corpus. When the accent sensitivity option is off (NO, the default choice), searching más will retrieve all instances of both más and mas in the corpus. When it is on (YES), the same search will only retrieve instances of más but exclude all mas forms. Similarly, when the case box is not active, the tool will search the word in the corpus irrespective of the case options; thus, when we type English in the search box, the search will retrieve all instances of English and english in the texts. If the case box were active, all instances of english would be excluded from the results.
Both the Word and the Word prox. searches may yield three types of results, which we may select by clicking on the Results type box:
The Simple frequency provides basic quantitative information on the occurrences of the searched word or expression in a section of the corpus defined by the user: the ratio of occurrences per total number of words, the normalized frequency per million words (in brackets) and the ratio of messages containing the word or expression per total number of messages. By clicking on the highlighted total number of occurrences, we obtain a list of concordances (see Figure 2) with all the examples of the searched word in context.
Figure 2 The "word prox" search screen.
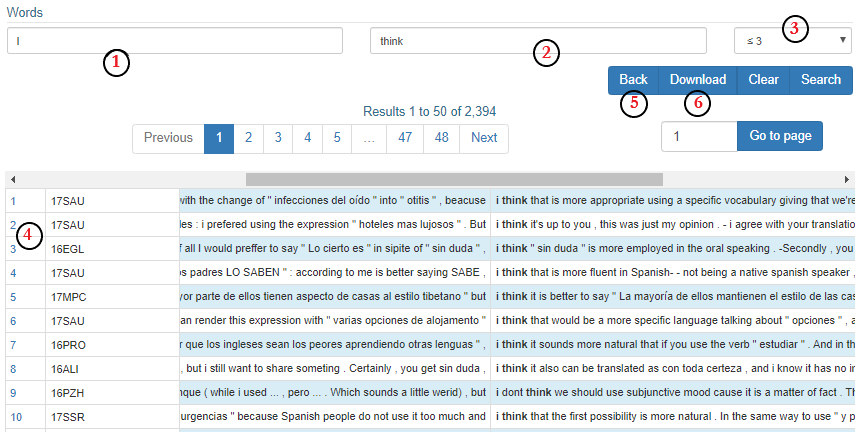
Notice: to return to any previous screen, use the Back button provided to the right of your screen (⑤); using your browser’s back button would clear the current search and bring you back to the Home screen!
The Full frequencies results screen provides the same information as the simple frequency results, this time broken down by year, sex, individual user, and L1 by sex on separate tables. Again, clicking on the highlighted figure containing the total number of occurrences gives a list of concordances with all the examples.
The KWIC results screen yields a list of concordances with all the examples of the word in the specified section of the corpus in their immediate context of occurrence. The right-most column contains the actual examples, with the key word bolded and aligned at the center, preceded and followed by some co-text. There are two other columns (④), containing the poster’s (coded) name and the example’s number (leftmost column) (concordances are displayed in a chronological order). Hovering the cursor over the poster’s name activates a box containing detailed information on the context of production of the retrieved excerpt: user id., thread language, user L1, sex, source text, thread id., date, time and message type. Clicking on the highlighted example number provides the wider context of the example: a new results screen is opened with the message where the example appears, highlighted in blue background and with the key word bolded, together with the two posts that chronologically preceded and followed the post in the thread. Clicking on the ^ symbol to the left of any of the 5 messages shows a header with full information on their context of production. Remember that, to return to the preceding screens, always press the Back button to the right of the screen.
KWIC search results may be sorted (Sorting) according to one or a combination of the following sorting fields, which may be activated by clicking on the blue question mark to the right of the sorting box: user, language, sex, source text, date, previous word, second previous word, next word and second next word. Notice that several sorting fields can be selected. When you use multiple fields to sort a view, the elements in it are grouped by the values of your primary sort field. Then, the elements in each of these groups are further organized using the values of your second and third sort selections. For example, results of a KWIC search of the word translation may be sorted primarily by previous word, secondly by second previous word and finally by sex to identify positive or negative adjective collocates, as well as the intensifiers or downtoners that may precede these adjectives. The Sorting function is not active for other result types, which is indicated by a red question mark.
The page size function allows us to choose the number of examples displayed by page to facilitate the visualization of the results. This option will be particularly relevant if we wish to download the results, as each page of results is downloaded as a separate file (see below).
Wildcards
SUNCODAC has not been POS-tagged nor lemmatized, two affordances which would represent a significant improvement to the tool’s search capabilities. As of today, all variants of a single lemma (e.g., translate, translated and translation) must be searched separately and word class-based searches (e.g., automatic retrieval of all adjectives preceding translation) must be done manually. Some of these limitations may be partly overcome by a clever use of the system’s wildcards. The * wildcard may be used to replace any word or character combination. Thus, transl* would retrieve all instances of translate, translated and translation. The ? wildcard may be used to replace any single character, which may be useful, for instance, to identify all forms of an English irregular verb like run: typing r?n would retrieve all instances of run and ran in the posts.
Downloading results
Search results in the KWIC and browsing output options can be downloaded (⑥ in Figure 2) as a CSV file which can be imported into any standard spreadsheet programmes so that metadata and text portions are displayed in separate columns. In the KWIC-type format (Figure 3), the search term(s) and each of the fragments defined by it are presented in three separate columns. With the browsing function, the full text of the post may be presented in a single column or —in the case of the message type labelled as "feedback"— divided into sections and spread across five columns (Figure 4 shows a partial view).
Figure 3 KWIC output imported into spreadsheet.

Figure 4 Browsing output (sections option, partial view) imported into spreadsheet.

The downloading function generates a separate file for each page of results displayed. Unfortunately, page size can be set to a maximum of 1,000 hits. Increasing this limit may also significantly increase processing time. Note also that when importing data into a spreadsheet programme the Unicode (UTF-8) character set should be selected for accents in the Spanish texts to be correctly displayed.